Basisvaardigheden in R: Werken met datastructuren
 Tabel
Tabel
- Wat is een tabel in R?
- Eerste R voorbeeld van een frequentietabel: een boekenverzameling
- Tweede voorbeeld van een frequentietabel en een staafdiagram: simulatie van dobbelsteenworpen
- R voorbeeld van een kruistabel
- R voorbeeld van een drievoudige kruistabel
- Lijst van functies voor creatie en manipulatie van tabellen in R
- Oefening
Wat is een tabel in R? In R wordt het object dat is gemaakt met de functie table() meestal een frequentietabel of een kruistabel genoemd, waarin categorische gegevens worden samengevat, dat wil zeggen, gegevens die kenmerken van individuen of objecten benoemen die geen grootte op een numerieke schaal hebben.
Een frequentietabel bestaat uit slechts twee kolommen: één voor de categorische variabele en één voor de absolute frequentie van elke categorie in een dataset. Het kan grafisch worden weergegeven in een staafdiagram of worden samengevat in een histogram. Wanneer de absolute frequenties worden gedeeld door het totale aantal objecten in de dataset, geven de getallen een verhouding of relatieve frequentie aan (of een percentage wanneer we ook vermenigvuldigen met 100), en dan krijgen we de relatieve frequentieverdeling, ook wel de kansverdeling van de categorische variabele genoemd.
Een voorbeeld is een verzameling boeken die zijn gecategoriseerd op basis van genre, en voor elke categorie (hier onderscheiden we drie categorieën: 'Fantasy', 'Science fiction' en 'Thriller') telt men het aantal boeken dat tot de categorie behoort. Dan kan de (absolute) frequentietabel er als volgt uitzien:
| Boek genre (categorische variabele) |
Aantal boeken in elk genre (absolute frequentie) |
| Fantasy | 11 |
| Science fiction | 15 |
| Thriller | 6 |
Een kruistabel (ook wel kruistabulatie, contingentietabel of tweeweg-tabel genoemd) is een absolute frequentietabel voor twee (of meer) categorische variabelen. Het geeft de absolute frequenties weer van alle combinaties van twee (of meer) categorische variabelen. In het onderstaande voorbeeld beschouwen we een groep mensen en gebruiken we twee categorische variabelen met elk twee categorieën: oogkleur (blauw of bruin) en het gebruik van visuele hulpmiddelen (wel of geen brildrager). Dan zou de kruistabel met absolute frequenties er als volgt uit kunnen zien:
| brildrager |
||
| oogkleur | ja |
nee |
| blauw |
7 | 18 |
| bruin | 12 | 34 |
Heel vaak worden voor data-analyse doeleinden de totale sommen van rijen en kolommen toegevoegd; deze sommen worden de marginale totalen genoemd, in meer detail de rij- en kolomtotalen. In ons voorbeeld zou de frequentietabel er als volgt uitzien:
| brildrager |
|||
| oogkleur | ja |
nee |
rijtotaal |
| blauw |
7 | 18 | 25 |
| bruin | 12 | 34 | 46 |
| kolomtotaal |
19 | 52 | 71 |
Overigens zijn de waargenomen en verwachte waarden van oogkleur en het gebruik van een bril in dit voorbeeld hetzelfde, zoals kan worden gecontroleerd aan de hand van de gegeven rij- en kolomtotalen van de waargenomen gegevens.
Eerste R voorbeeld van een frequentietabel: een boekenverzameling Hoe maak je een tabel in R, of preciezer gezegd, hoe maak je een frequentietabel? Het basisidee is dat je eerst een vector maakt waarin je voor elk object in je dataset de overeenkomstige categorie in de categorische variabele, waarin je geïnteresseerd bent, opsomt. Vervolgens pas je de functie table() toe op de datavector om de frequentietabel te genereren.
Dit illustreren we aan de hand van een voorbeeld van een denkbeeldige, kleine privéverzameling van boeken. Stel dat deze verzameling bestaat uit 9 boeken die tot 4 genres behoren: Thriller, Fantasy, Science fiction en Detective. Het genre van het boek is dus de categorische variabele waarin we geïnteresseerd zijn. Eerst maak je een vector, laten we zeggen "boeken", waarin het genre van elk boek in de collectie wordt vermeld.
> boeken <- c("Thriller", "Thriller", "Fantasy", "Detective", "Detective", + "Thriller", "Fantasy", "Detective", "Science fiction")
Om de absolute frequentietabel van de gegeven dataset te maken, laten we deze abs..freq.tabel noemen, hoef je alleen maar de functie table() toe te passen op de vector die je zojuist hebt gemaakt. De R-functie doet al het tellen voor je!
> abs_freq_tabel <- table(boeken) > abs_freq_tabel boeken Detective Fantasy Science fiction Thriller 3 2 1 3
Om de relatieve frequentietabel te maken, kun je basisberekeningen gebruiken en de instructie abs_freq_tabel/length(boeken) invoeren, of je kunt in plaats daarvan de ingebouwde functie prop.table() gebruiken; vermenigvuldig met 100 om de relatieve frequenties als percentages te krijgen.
> abs_freq_tabel / length(boeken) boeken Detective Fantasy Science fiction Thriller 0.3333333 0.2222222 0.1111111 0.3333333 > prop.table(abs_freq_tabel) boeken Detective Fantasy Science fiction Thriller 0.3333333 0.2222222 0.1111111 0.3333333 > prop.table(abs_freq_tabel)*100 boeken Detective Fantasy Science fiction Thriller 33.33333 22.22222 11.11111 33.33333
Tweede R voorbeeld van een frequentietabel en een staafdiagram: simulatie van dobbelsteenworpen In het tweede voorbeeld simuleren we het gooien van een eerlijke dobbelsteen en maken we op dezelfde manier een frequentietabel als in het vorige voorbeeld, maar nu voor de categorische variabele van mogelijke uitkomsten van een worp met een dobbelsteen. Daarnaast laten we zien hoe een staafdiagram kan worden gemaakt.
Eerst stellen we de sleutel of `seed' van onze willekeurige getallengenerator in, zodat we dezelfde data krijgen gegenereerd telkens wanneer we de steekproefsessie herhalen. We genereren een willekeurige reeks uitkomsten van het gooien met een dobbelsteen.
> set.seed(123) > worpen <- sample(1:6, size=50, replace=TRUE)
Het maken van de frequentietabel wordt gedaan met behulp van de functie table():
> abs_freq_tabel <- table(worpen) > abs_freq_tabel worpen 1 2 3 4 5 6 9 8 11 6 9 7
We zetten het om in een relatieve frequentietabel met behulp van de functie prop.table() (afkorting van proportion table):
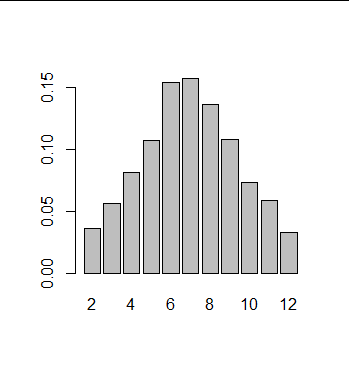
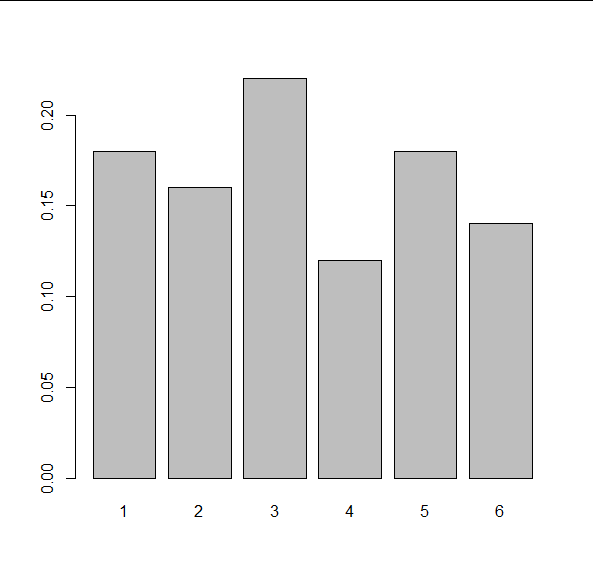
> rel_freq_tabel <- prop.table(abs_freq_tabel) > rel_freq_tabel worpen 1 2 3 4 5 6 0.18 0.16 0.22 0.12 0.18 0.14
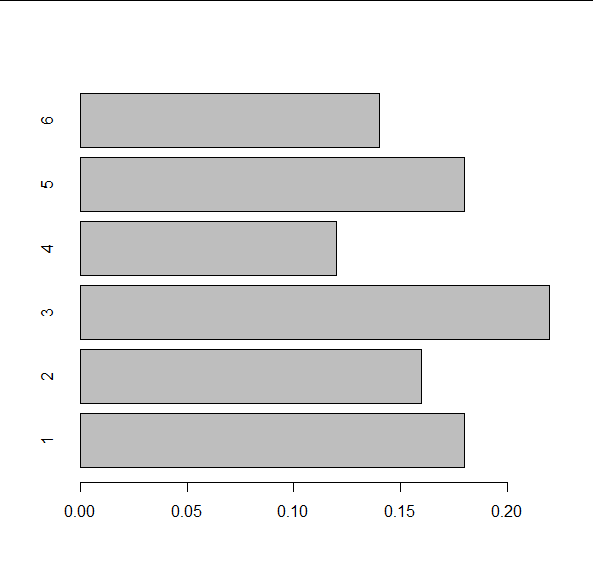
We kunnen de relatieve frequentietabel visualiseren als een staafdiagram met behulp van de functie barplot() waarbij de optie true/false voor horiz bepaalt of we verticale staafjes (standaard) of horizontale staafjes hebben::
> barplot(rel_freq_tabel)
> barplot(rel_freq_tabel, horiz=TRUE)
Elegantere staafdiagrammen kunnen in R worden gemaakt met het pakket ggplot2.
R voorbeeld van een kruistabel Voor kruistabellen is het formaat voor de functie table() gelijk aan kruistabel <- table(A,B)waarbij A de rijvariabele is en B de kolomvariabele, beide zijnde vectoren. In ons voorbeeld is de categorische rijvariabele de sekse (letter "M" voor mannelijk en "V" voor vrouwelijk) van personen in een bepaalde groep aan wie we hebben gevraagd wat hun favoriete smaak ijs is (de categorische variabele met letters "C" voor Chocolade, "A" voor Aardbei en "V" voor Vanille).
Onze voorbeeldsessie begint met het invoeren van de gegevens in twee vectoren, gevolgd door het maken van de kruistabel. We volgen hier de conventie om de nominale gegevens (man en vrouw) in de rijen te plaatsen en de ordinale gegevens (de drie smaken) in de kolommen.
> sekse <- c("M", "V", "M", "M", "V", "V", "M", "V")
> voorkeur <- c("C", "V", "V", "C", "C", "A", "A", "C")
> kruistabel <- table(sekse, voorkeur)
> kruistabel voorkeur sekse A C V M 1 2 1 V 1 2 1
Om de uitvoer beter leesbaar te maken kun je de rij- en kolomnamen veranderen via de functie dimnames():
> dimnames(kruistabel)[[1]] <- c("man", "vrouw") > dimnames(kruistabel)[[2]] <- c("aardbeien", "chocolade", "vanilla") > kruistabel voorkeur sekse aardbeien chocolade vanilla man 1 2 1 vrouw 1 2 1
Je kunt de functie addmargins() gebruiken om rij- en kolomtotalen toe te voegen aan een kruistabel.
> addmargins(kruistabel)
voorkeur
sekse aardbeien chocolade vanilla Sum
man 1 2 1 4
vrouw 1 2 1 4
Sum 2 4 2 8
> addmargins(kruistabel, FUN = list(list(Totaal = sum)))
Margins computed over dimensions
in the following order:
1: sekse
2: voorkeur
voorkeur
sekse aardbeien chocolade vanilla Totaal
man 1 2 1 4
vrouw 1 2 1 4
Totaal 2 4 2 8
Verhoudingen kunnen worden berekend met behulp van de functie prop.table() met betrekking tot rijen (optie margin=1) of kolommen (margin=2).
> prop.table(kruistabel, margin=1) voorkeur sekse aardbeien chocolade vanilla man 0.25 0.50 0.25 vrouw 0.25 0.50 0.25
> addmargins(prop.table(kruistabel, margin=1), margin=2, FUN=list(list(Totaal=sum))) voorkeur sekse aardbeien chocolade vanilla Totaal man 0.25 0.50 0.25 1.00 vrouw 0.25 0.50 0.25 1.00
Uit de bovenstaande contingentietabellen is meteen duidelijk dat er in onze verzonnen dataset geen verschil bestaat in voorkeur voor smaak van ijs tussen mannen en vrouwen.
> prop.table(kruistabel, margin=2) voorkeur sekse aardbeien chocolade vanilla man 0.5 0.5 0.5 vrouw 0.5 0.5 0.5 > addmargins(prop.table(kruistabel, margin=2), margin=1, FUN=list(list(Totaal=sum))) voorkeur sekse aardbeien chocolade vanilla man 0.5 0.5 0.5 vrouw 0.5 0.5 0.5 Totaal 1.0 1.0 1.0Zonder de richtingen berekent,
prop.table() de relatieve frequenties van de cellen met betrekking tot de grootte van de groep van personen. > addmargins(prop.table(kruistabel), FUN=list(list(Totaal=sum))) Margins computed over dimensions in the following order: 1: sekse 2: voorkeur voorkeur sekse aardbeien chocolade vanilla Totaal man 0.125 0.250 0.125 0.500 vrouw 0.125 0.250 0.125 0.500 Totaal 0.250 0.500 0.250 1.000
R voorbeeld van een drieweg-tabel Als voorbeeld van een drieweg-tabel gebruiken we de Artritis dataset die is opgenomen in het pakket vcd. De gegevens zijn afkomstig van
Koch, G. and S. Edwards (1988). Clinical efficiency trials with categorical data. In: K. E. Peace (Ed.), Biopharmaceutical Statistics for Drug Development (pp. 403–451) New York: Marcel Dekker
Also in: Statistical Analysis with Missing Data (2nd ed., Eds. R. J. A. Little and D. Rubin) Hoboken, NJ: John Wiley & Sons, 2002.
Het representeert een dubbelblinde klinische proef van nieuwe behandelingen voor reumatoïde artritis.
In de voorbeeldsessie installeren we eerst het pakket vcd met de functie install.packages() en activeren dit pakket met de functie library(); Negeer voorlopig de feedbackberichten in het consolevenster.
> install.packages("vcd")
> library(vcd)
De eerste paar gegevens kunnen worden bekeken met behulp van de functie head():
> head(Arthritis) ID Treatment Sex Age Improved 1 57 Treated Male 27 Some 2 46 Treated Male 29 None 3 77 Treated Male 30 None 4 17 Treated Male 32 Marked 5 36 Treated Male 46 Marked 6 23 Treated Male 58 Marked
Het Arthritis object is een data frame, een data structuur die we later zullen bespreken. Het bevat echter drie categorische variabelen: Treatment (Placebo, Treated), Sex (Male, Female), en Improved (None, Some, Marked). Hieronder gebruiken we de functie with() zodat we de namen van de categorische variabelen kunnen gebruiken zonder constant lange namen te hoeven gebruiken die verwijzen naar het Arthritis object, zoals Arthritis$Treatment. Wanneer we de drieweg-tabel bekijken die we maken met table(), krijgen we voor elke seksecategorie een kruistabel van de twee categorische variabelen Treatment en Improved.
> drieweg_tabel <- with(Arthritis, table(Treatment, Improved, Sex)) > drieweg_tabel , , Sex = Female Improved Treatment None Some Marked Placebo 19 7 6 Treated 6 5 16 , , Sex = Male Improved Treatment None Some Marked Placebo 10 0 1 Treated 7 2 5
Rij- en kolomtotalen kunnen opnieuw weer toegevoegd worden m.b.v. de functie addmargins().
> addmargins(drieweg_tabel, margin=c(1,2))
, , Sex = Female Improved Treatment None Some Marked Sum Placebo 19 7 6 32 Treated 6 5 16 27 Sum 25 12 22 59 , , Sex = Male Improved Treatment None Some Marked Sum Placebo 10 0 1 11 Treated 7 2 5 14 Sum 17 2 6 25
Een meer compacte, 'platgeslagen' tabel kan met de functie ftable() gemaakt worden.
> ftable(drieweg_tabel) Sex Female Male Treatment Improved Placebo None 19 10 Some 7 0 Marked 6 1 Treated None 6 7 Some 5 2 Marked 16 5
Lijst van functies voor het creëren en manipuleren van tabellen in R
| Functie | Beschrijving |
table(var1, var2, ..., varN) |
Maak een Nweg-tabel van N categorische variabelen; een éénweg-tabel is beter bekend als frequentietabel. |
prop.table(table, margin=...) |
Druk tabelcomponenten uit als fracties van de totalen die gedefinieerd worden door de margin optie. |
addmargins(table, margin=...) |
Voeg totalen toe die gedefinieerd zijn door de margin optie. |
ftable(table) |
Maak een meer compacte, 'platgeslagen' contingentietabel van een gegeven tabel. |
dimnames(table) |
Bepaal of stel de dimensienamen van de gegeven tabel in. |
Oefening 1. Artritis voorbeeld
We werken door met de Artritis gegevens uit het pakket vcd en vragen je om
- een frequentietabel te maken van de categorische variabele
Improveden om een staafdiagram van de frequentietabel te tekenen; - een tweeweg-tabel te maken van de variabelen
TreatmentenImproved.
2. Willekeurig kegels oppakken
Stel je voor dat je willekeurig een aantal kegels oppakt die elk groen, geel, rood of paars gekleurd zijn. Laten we de frequenties van elke kleur in de greep tellen en een frequentietabel hiervan maken die ook totalen bevat voor de volgende geordende greep:
mijn_greep <- c("groen", "groen", "groen", "groen", "geel", "geel",
"geel", "rood", "rood", "paars", "paars", "paars")
Maak ook een staafgrafiek van de frequentietabel.
3. Twee dobbelstenen gooien
Maak in R een simulatie van 1000 willekeurige worpen met twee eerlijke dobbelstenen. Maak een frequentietabel van een dobbelsteenworp 'uitkomst van een worp' voor jouw simulatie. Maak ook een staafgrafiek van de relatieve frequentietabel.
Oplossing 1 1. Artritis voorbeeld
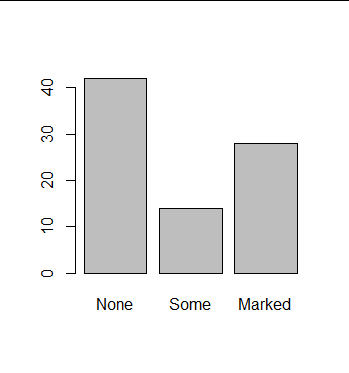
> install.packages("vcd") > library(vcd) > freq_tabel <- with(Arthritis, table(Improved)) > freq_tabel Improved None Some Marked 42 14 28 > barplot(freq_tabel)
> tweeweg_tabel <- with(Arthritis, table(Treatment,Improved)) > tweeweg_tabel Improved Treatment None Some Marked Placebo 29 7 7 Treated 13 7 21
Oplossing 2
2. Willekeurig kegels oppakken
> mijn_greep <- c("groen", "groen", "groen", "groen", "geel", "geel",
+ "geel", "rood", "rood", "paars", "paars", "paars")
> freq_tabel <- table(mijn_greep)
> addmargins(freq_tabel, FUN=list(list(Totaal=sum)))
mijn_greep
geel groen paars rood Totaal
3 4 3 2 12
> barplot(freq_tabel)

Oplossing 3 3. Met twee dobbelstenen gooien
> set.seed(123) > worp_dobbelsteen1 <- sample(1:6, size=1000, replace=TRUE) > worp_dobbelsteen2 <- sample(1:6, size=1000, replace=TRUE) > worpen <- worp_dobbelsteen1 + worp_dobbelsteen2 > rel_freq_tabel <- prop.table(table(worpen)) > rel_freq_tabel worpen 2 3 4 5 6 7 8 9 10 12 0.08 0.04 0.04 0.06 0.08 0.20 0.22 0.16 0.10 0.02 > barplot(rel_freq_tabel)