Basisvaardigheden in R: Werken met datastructuren
 Dataframe
Dataframe
Een dataframe heeft rijen en kolommen zoals een matrix, maar een matrix moet gevuld zijn met waarden van hetzelfde datatype, terwijl een dataframe waarden van verschillende datatypen kan bevatten. Kijk eens naar het onderstaande dataframe, dat we zullen gebruiken in de onderstaande voorbeeldsessies van R, en dat een kleine dataset van mensen is. De kolommen Leeftijd en Lengte bevatten numerieke waarden, terwijl de kolommen Naam en Sekse karakterwaarden bevatten. Elke rij bevat één set waarden voor één persoon, gelabeld met een identiteitsnummer Id.
| Id | Naam | Leeftijd | Sekse | Lengte |
| 1101 | Jan | 25 | mannelijk | 180 |
| 2223 | Anna | 30 | vrouwelijk | 165 |
| 1301 | Michael | 28 | mannelijk | 175 |
| 4001 | Sofie | 22 | vrouwelijk | 160 |
| 2262 | Michael | 32 | mannelijk | 174 |
Dataframes worden veel gebruikt in onderzoek, dus het is handig om te weten hoe je ermee moet werken.
Uitleg
Om een dataframe te maken, kun je de functie data.frame() gebruiken. Deze functie vereist vectoren als invoer. Elke vector wordt dan een nieuwe kolom in het dataframe. Je kunt de vectoren rechtstreeks tussen de haakjes van de functie data.frame() plaatsen of je kunt de vectoren eerst buiten deze functie aanmaken en ze daarna invoegen.
Via de functie dim() kun je de dimensie van een dataframe weergeven. Het aantal rijen en kolommen kan ook worden verkregen door respectievelijk de functie nrow() en ncol() . De interne structuur kan worden weergegeven via de functie str(). Het laat zien dat de functie data.frame() de karakter vectoren heeft omgezet in zogenaamde factoren, waarin categorische waarden intern als getallen zijn opgeslagen.
De optie row.names=... specificeert de kolomnaam die moet worden gebruikt bij het labelen van gevallen op allerlei afdrukken en grafieken. Je kunt vragen stellen over de rij- en kolomnamen die in een dataframe worden gebruikt door respectievelijk de functies rownames() en names().
Voorbeeldsessie

Een dataframe bekijken via de Data Viewer Wanneer je een variabele maakt die een dataframe opslaat, zie je daarachter een klein pictogram in het paneel Environment/History/Connections (in een tabblad in het paneel rechtsboven in R). In ons geval ziet het er als volgt uit met een toegevoegde rode pijl die naar het pictogram wijst:.

Wanneer je op het pictogram klikt, wordt het dataframe geopend op een nieuw tabblad in het source panel linksboven, en kun je het dataframe in spreadsheet-stijl bekijken. In ons geval presenteert de dataviewer het dataframe persoonsgegevens als volgt:

De Data Viewer had ook kunnen worden aangeroepen voor het dataframe persoonsgegevens door de R-instructie View(persoonsgegevens).
Uitleg
Net als vectoren en matrices zijn dataframes indexeerbare en veranderlijke objecten. We gebruiken de dataframe persoonsgegevens om uit te leggen hoe je een element van het dataframe kunt selecteren en wijzigen.
Je kijkt naar het dataframe persoonsgegevens en je ziet bijvoorbeeld dat Anna's lengte zich bevindt in rij 2, kolom 5. Je kunt dit element selecteren met een positionele index [2,5]. Als alternatief kun je rij- en kolomnamen gebruiken. Je kunt de waarde hiervan wijzigen en dit verandert ook het dataframe.
Soms werk je met een dataframe dat een waanzinnig aantal rijen heeft. Laten we ons voorstellen dat ons dataframe eigenlijk veel langer was, dan zou het te lang duren om daar doorheen te scrollen totdat je Anna's rij hebt gevonden. Ervan uitgaande dat er een unieke Anna in de dataset zit, kun je de instructie persoonsgegevens[persoonsgegevens$Naam =="Anna", "Lengte"]
gebruiken.
Voorbeeldsessie

Het idee van deze instructie is als volgt:
persoonsgegevensis het dataframe waaruit een element moet worden geselecteerd;- het 1ste argument informeert R om op te zoeken in welke rij in
persoonsgegevensde naam Anna voorkomt in de kolomNaam; - het tweede argument informeert R om de kolom
Lengtete gebruiken.
Indien een naam (zoals Michaël) meerdere keren voorkomt in de kolom Naam, krijg je alle rijen waarin deze naam voorkomt. In de voorbeeldsessie vinden we op deze manier de Id's van alle personen in de dataset die Michael heten.
Je kunt ook nieuwe dataframes maken met behulp van selectiemethoden. In de voorbeeldsessie krijgen we bijvoorbeeld een dataframe met de namen en leeftijden van alle personen met een lengte gelijk aan 160.
De rijnamen van een dataframe kunnen worden teruggezet naar de standaardnamen door toewijzing van het lege object NULL.
Werken met dataframes
Uitleg
We blijven werken met de dataframe persoonsgegevens die we eerder hebben gemaakt.
Laten we aannemen dat we alleen de kolommen willen zien die zijn gelabeld met Naam en Lengte. We kunnen ze selecteren door een vector van kolomnummers en door een vector van kolomnamen; zie de eerste instructies in de voorbeeldsessie aan de rechterkant.
Je kunt een enkele kolom selecteren, bijvoorbeeld de Id kolom, met de instructie persoonsgegevens[ ,"Id"] (merk op dat er nog steeds een komma staat om het eerste element van het tweede element te scheiden binnen de vierkante haken!), maar het is eenvoudiger om de leeftijdsvariabele in het dataframe in te voeren als persoonsgegevens$Leeftijd. De $-notatie wordt gebruikt om een specifieke kolomvariabele uit een bepaald dataframe aan te duiden. Als we bijvoorbeeld de gemiddelde, minimale en maximale leeftijd van alle personen in onze dataset willen berekenen, kunnen we de volgende code gebruiken:c(mean(persoonsgegevens$Leeftijd),.
min(persoonsgegevens$Leeftijd),
max(persoonsgegevens$Leeftijd))
Voorbeeldsessie

Het kan vermoeiend zijn om persoonsgegevens$ aan het begin van elke variabelenaam te typen, maar de functie with() kan de code vereenvoudigen:with(persoonsgegevens, c(mean(Leeftijd), min(Leeftijd), max(Leeftijd)))
is korter en beter leesbaar. Overigens zou de functie summary() de handigste manier zijn geweest om beschrijvende statistiek voor de leeftijdsvariabele uit te voeren.
Net als vectoren en matrices maken dataframes in R de selectie van componenten mogelijk met behulp van logische expressies; zie de laatste drie instructies is de voorbeeldsessie.
Een andere manier om gegevens uit een dataframe te filteren is door de functie subset() te gebruiken. Deze functie hoeft slechts twee dingen van je te weten:
- de naam van het dataframe;
- de voorwaarde om rijen te selecteren.
subset(persoonsgegevens, Leeftijd>25 & Leeftijd<30)Oefening
1. logaritmische tabel
- Maak een dataframe dat je kunt gebruiken als opzoektabel voor logaritmen. De eerste kolom bevat de waarden waarvoor je de logaritme wilt berekenen: laat dit de getallen \[1,2,3,\ldots 9, 10, 20, 30, \ldots 90, 100, 200, 300, \ldots , 1000\] zijn. De volgende kolommen bevatten de functiewaarden voor de logaritmen met respectievelijk grondtal \(2\), \(e\), \(3\) en \(10\). Toon de eerste paar regels van het dataframe.
- Verwijder de kolom in het dataframe met waarden van de logaritme met grondtal \(3\).
2. Brandstofverbruik van auto's
R heeft het ingebouwde dataframe mtcars, afkomstig uit het Motor Trend US-tijdschrift uit 1974. Het bevat gegevens over brandstofefficiëntie, afhankelijk van 10 aspecten van het auto-ontwerp voor 32 autotypes.
- Zoek uit welke gegevens zijn verzameld en om welke autotypes het gaat.
- Maak een samenvatting, in beschrijvende statistiek zin, van de variabele mijlen per gallon.
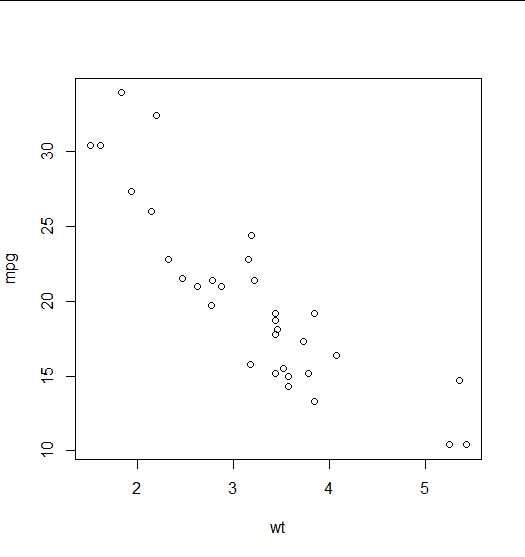
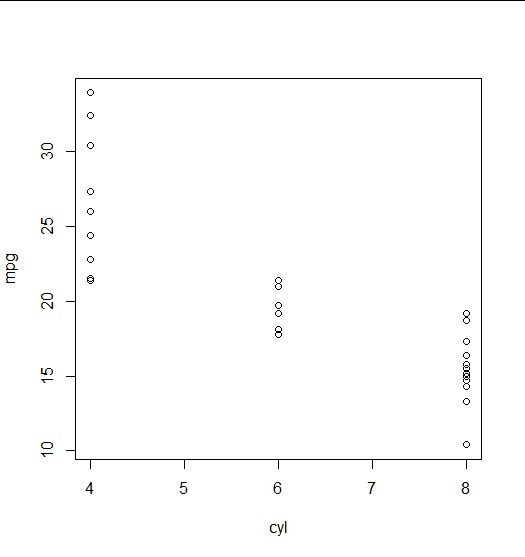
- Teken puntgrafieken van mijlen per gallon tegen gewicht van de auto en tegen aantal cilinders.
- Wat zijn de namen van de auto's waarvoor de mijlen per gallon groter is dan 25 en de 1/4 mijl-tijd minder dan 18 seconden is?
> rownames(mtcars) [1] "Mazda RX4" "Mazda RX4 Wag" [3] "Datsun 710" "Hornet 4 Drive" [5] "Hornet Sportabout" "Valiant" [7] "Duster 360" "Merc 240D" [9] "Merc 230" "Merc 280" [11] "Merc 280C" "Merc 450SE" [13] "Merc 450SL" "Merc 450SLC" [15] "Cadillac Fleetwood" "Lincoln Continental" [17] "Chrysler Imperial" "Fiat 128" [19] "Honda Civic" "Toyota Corolla" [21] "Toyota Corona" "Dodge Challenger" [23] "AMC Javelin" "Camaro Z28" [25] "Pontiac Firebird" "Fiat X1-9" [27] "Porsche 914-2" "Lotus Europa" [29] "Ford Pantera L" "Ferrari Dino" [31] "Maserati Bora" "Volvo 142E" > names(mtcars) [1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" [9] "am" "gear" "carb" > # uitleg over namen krijg met de instructie ?mtcars in het console venster
> ?mtcars
> # beschrijvende statistiek > summary(mtcars$mpg) Min. 1st Qu. Median Mean 3rd Qu. Max. 10.40 15.43 19.20 20.09 22.80 33.90 > with(mtcars, {plot(wt, mpg) + plot(cyl, mpg)})
De twee grafieken zijn:
> with(mtcars, row.names(mtcars[mpg>25 & qsec<18, ])) [1] "Porsche 914-2" "Lotus Europa"


